
Increase functionality by actionable knowledge extraction
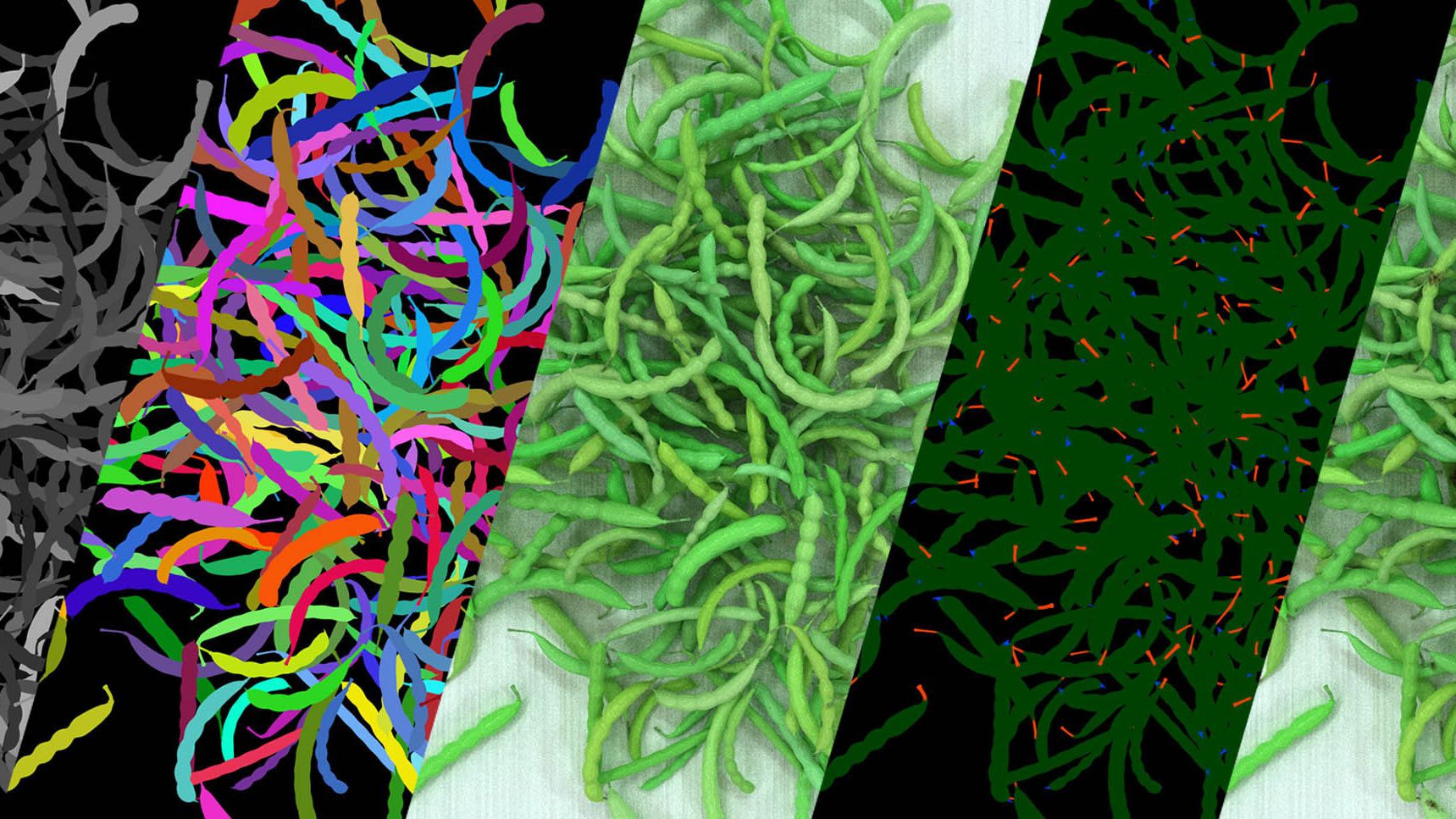
We work on the generation of synthetic datasets through simulation. Our systems are able to generate near-infinite permutations of complex, domain-specific, 3D environments. Within these environments, we can simulate a range of sensors, from standard RGB cameras to lidar, depth sensors, ultrasound, radar and more.
The known ground truth of the system, allows for highly consistent, rich annotation. This exciting approach opens new paths to machine learning where a lack of the right data is currently limiting.

A simulation consists of two main components:
A modular approach to the development of geometry generators and modifiers is key. A parametric interface for each of these modules allows for the controlled generation of near-infinite permutations of geometry, materials and behavior.
A combination of modules can be compiled into a new module with its own high-level interface. A network of these modules can generate complex environments. This architecture allows for a scriptable interface to the simulation and computing farm.
Besides the simulated sensor data, we can use the known ground truth to generate rich labeling. Essential in developing an effective synthetic model:
In the animation below, you find a clear visualization of the architecture of our simulations.
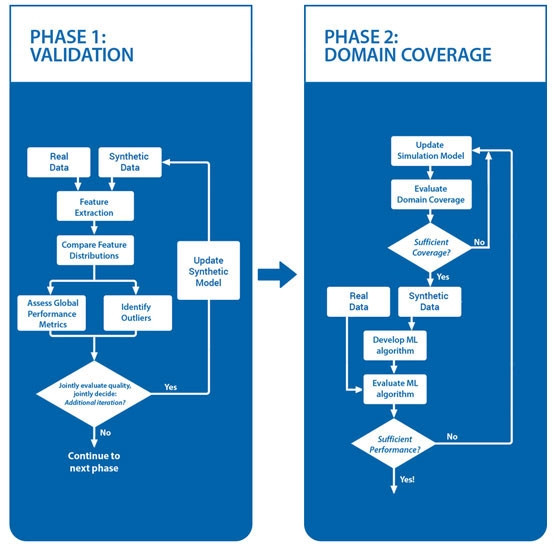
In a data-centric approach, we analyze the quality of the generated data by comparing the synthetic set to a small set of real-world data. This comparison is done in a suitable feature space.
Two important concepts to analyze are the fidelity (how much does the synthetic data resemble the real data) and the diversity (does the synthetic data cover all the variation from the real data).
A range of advanced metrics is used to gather actionable intelligence to refine the synthetic model and improve the generated datasets.
For all cases, we believe that close, iterative cooperation between the Al teams and the synthetic data team is key.
• as part of a larger Demcon high-tech or medical system- or product development
• as part of a vision or Al project
• or as a stand-alone service.
In the first phase of a typical project, we focus on reducing the domain gap between our simulation and a small set of real-world data if available. In the subsequent phase, we expand the simulation to cover the project domain.
Increase functionality by actionable knowledge extraction
More robust machine vision applications
Optimize machine operation quality
Optimize control and machine performance