highlights
- Enabling the development of novel algorithms through synthetic data
- A high level of control over the simulated sensor data and the annotation
- This pipeline opened new possibilities for future developments
the solution.
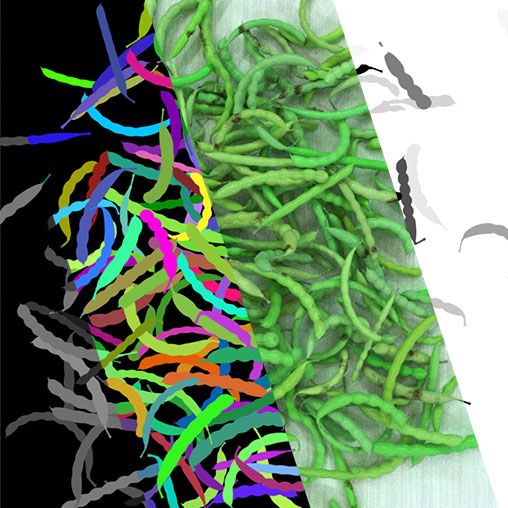
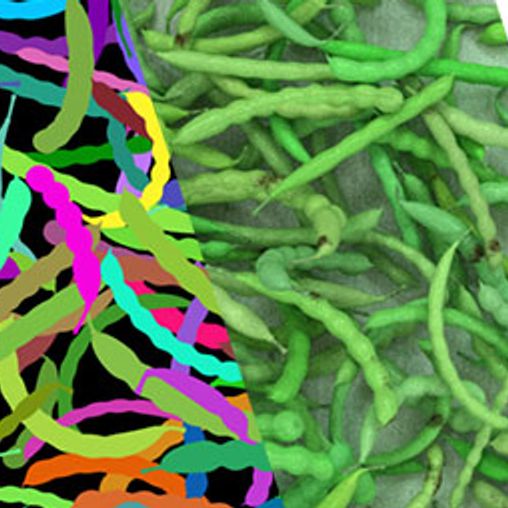
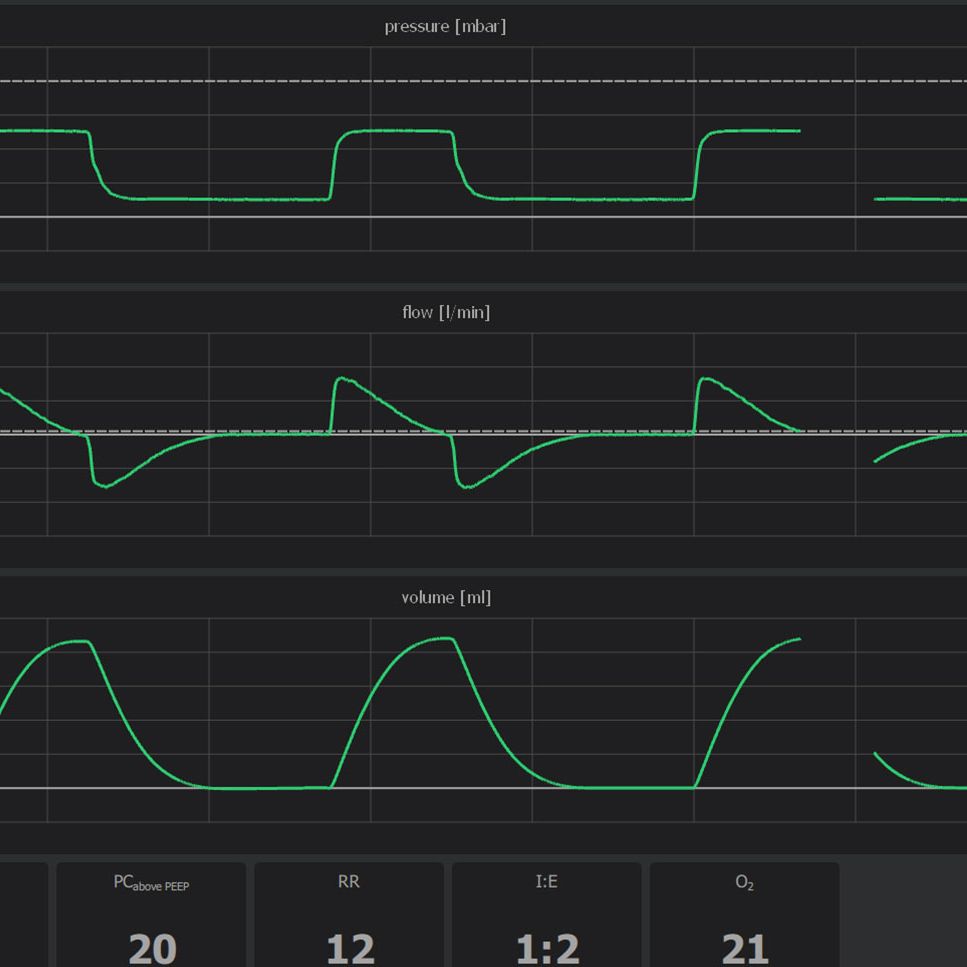
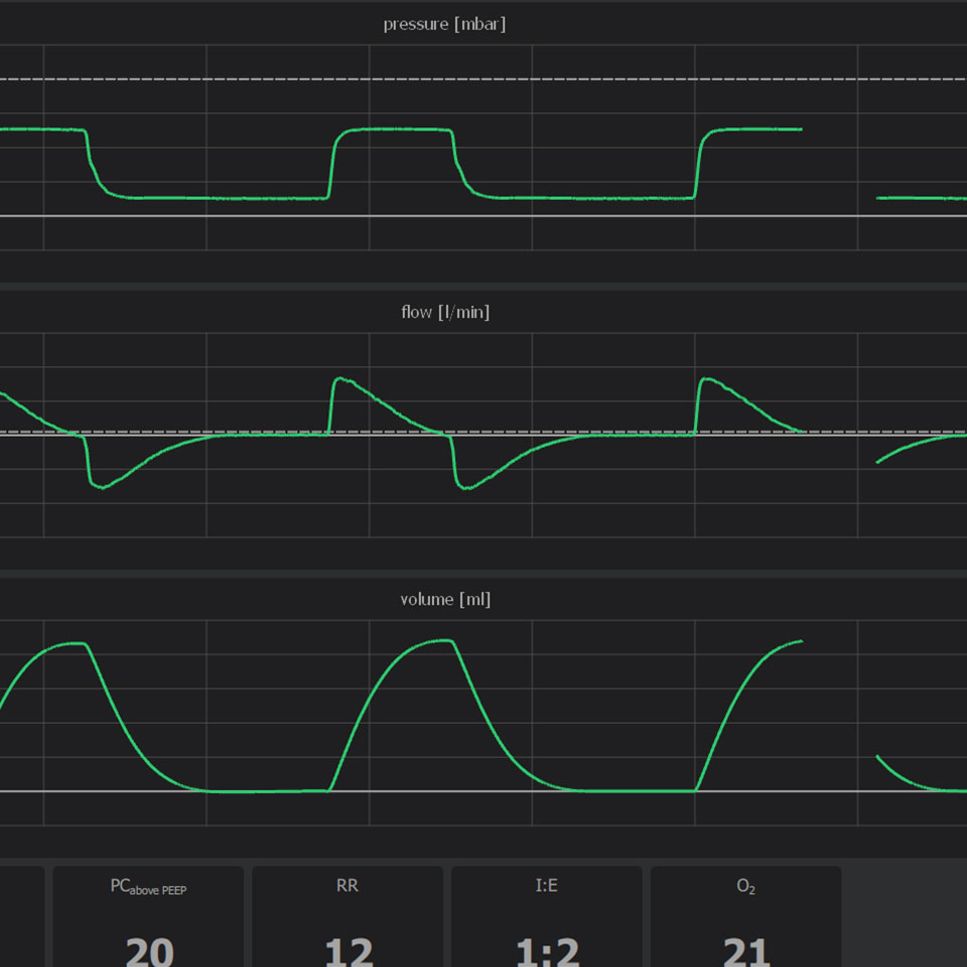
To generate a close synthetic dataset, the imaging setup – including lighting, environment and cameras – was reproduced in simulation. Inside this environment, a bean module was developed and employed. See our synthetic data section for more details on the architecture of these modules. Below you find a video to illustrate this bean module.
the results.
Our synthetic data pipeline enabled the generation of a varied dataset with highly consistent labeling. In the video Below, you find a selection of renders and annotations generated by the system.
synthetic data has the potential to unlock the use of machine learning where a lack of the right data is currently limiting.
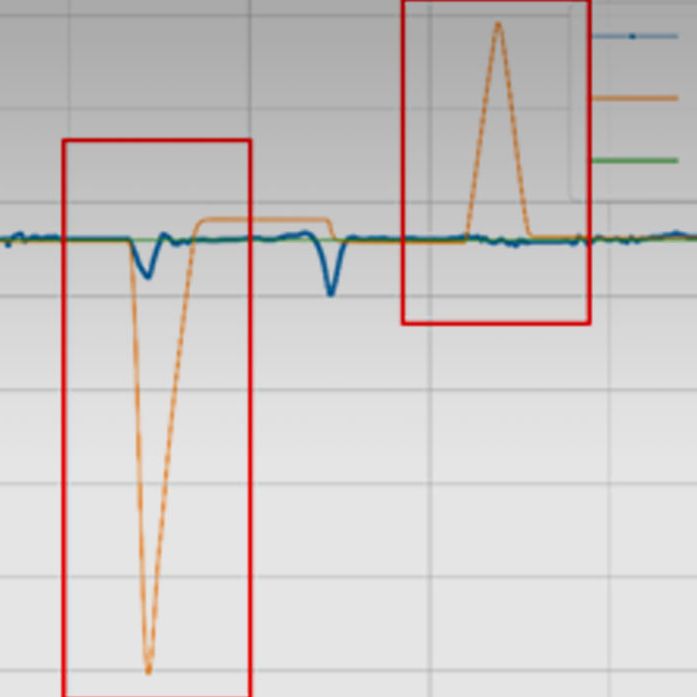
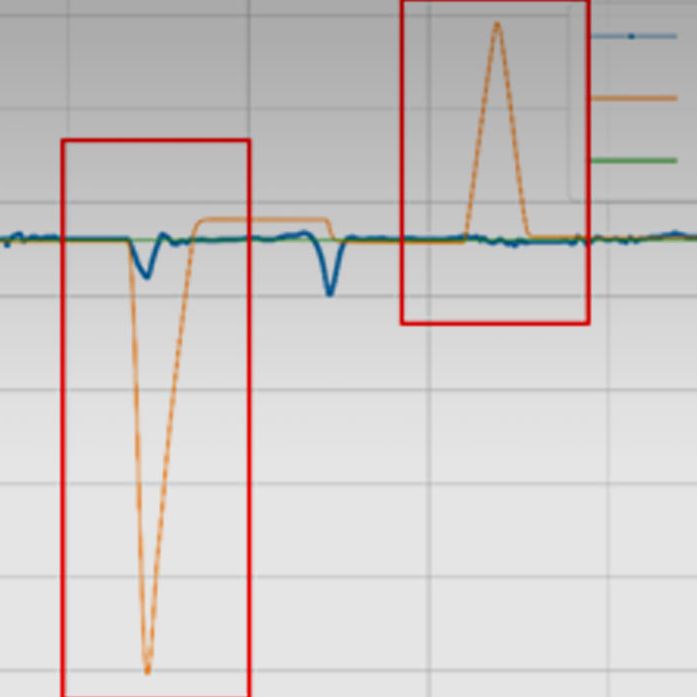
.jpg)
.jpg)