synthetic data for bin picking.
We were asked to develop a number of datasets to aid in the development of bin-picking algorithms. Identifying suitable picking surfaces for a vacuum cup is defined by a number of relatively simple rules. These rules however are almost impossible to consistently apply manually.
highlights
- Enabling the development of novel algorithms through synthetic data
- A high level of control over the simulated sensor data and the annotation; the ability to adjust annotation rules in post
- A level of consistency not feasible through manual annotation
- This pipeline opened new possibilities for future developments, including annotation of 3D objects through voxel data, object-oriented bounding box, surface normal vectors and more
the solution.
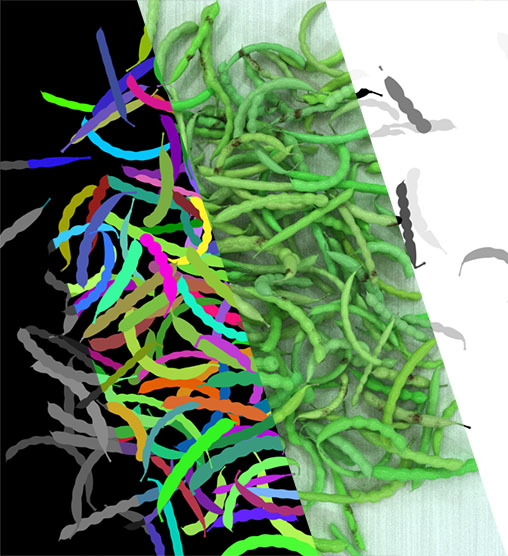
A large number of random objects was generated and placed inside a number of bins. In the video on the right, the project objects were replaced by dummy objects. Besides the RGB sensor, a depth sensor was simulated. This simulation included sensor-specific noise. Including specific behavior for transparent and metallic reflective surfaces.
the results.
As all our environments are defined in 3D, we can employ this ground truth to consistently generate annotation maps and develop a post-processing pipeline to adjust these annotations. In this use case, annotation was defined by a series of simple rules. For each of these rules, a separate grey-scale annotation map was generated. These grey-scale maps can be clamped in a separate pipeline to adjust the resulting annotation as desired in post.